Transformer (Vaswani et al. 2017)
1. Non-recurrent sequence model (or sequence-to-sequence model)
2. A deep model with a sequence of attention-based transformer blocks
3. Depth allows a certain amount of lateral information transfer in understanding sentences, in slightly unclear ways
4. Final cost/error function is standard cross-entropy error on top of a softmax classifier
https://econmacromicro.blogspot.com/p/nlp-papers-httpsarxiv.html
Attention
Attention is a mechanism is the neural network that a model can learn to make predictions by selectively attending attending to a given set of data. The amount of attention is quantified by learned weights and thus the output is usually formed as weighted average.
Self-attention is a type of attention mechanism where the model makes prediction for one part of a data sample using other parts of the observation about the same sample. Conceptually, it feels quite similar to non-local means. Also, note that self-attention is permutation invariant; in other words, it is an operation on sets.
There are various forms of attention / self-attention, Transformer relies on scaled-dot product attention: given a query matrix Q, a key matrix K and a value matrix V, the output is a weighted sum of the value vectors, where the weight assigned to each value slot is determined by dot-product of the query with the corresponding key:
And for a query and a key vector q_i,
Positional Encoding - The encoding proposed by authors
The encode is great at understanding text.The decoder is great at generating text.
----
The Taxonomy of the Transformer
● Encoder-Decoder Structure
● Positional Encoding
Transformer layers have no recurrence structure. Thus, the information about the relative position of the observations within the time series needs to be included in the model. To do so, a positional encoding is added to the input data. In the context of NLP, Vaswani et al. [54] suggested the following wave functions as positional encoders:
(sin for even and cos for odd positions)
● Multi-Head Attention Layer
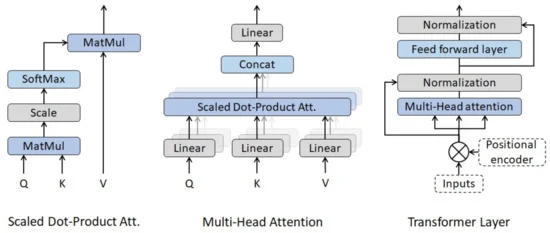
● Masking
● Residual Connections
● FeedForwardand NormalizationLayers
Transformer: A Novel Neural Network Architecture for Language Understanding (Jakob Uszkoreit, 2017) - The original Google blog post about the Transformer paper, focusing on the application in machine translation.
The Illustrated Transformer (Jay Alammar, 2018) - A very popular and great blog post intuitively explaining the Transformer architecture with many nice visualizations. The focus is on NLP.
Attention? Attention! (Lilian Weng, 2018) - A nice blog post summarizing attention mechanisms in many domains including vision.
Illustrated: Self-Attention (Raimi Karim, 2019) - A nice visualization of the steps of self-attention. Recommended going through if the explanation below is too abstract for you.
The Transformer family (Lilian Weng, 2020) - A very detailed blog post reviewing more variants of Transformers besides the original one.